|
|
You are here: Foswiki>DaqSlowControl Web>HadesDaqDocumentation>EventBuilder>EventBuilderTest (2010-11-29, SergeyYurevich)Edit Attach
Table of contents:
 daq_netmem CPU usage vs data rate:
daq_netmem CPU usage vs data rate:
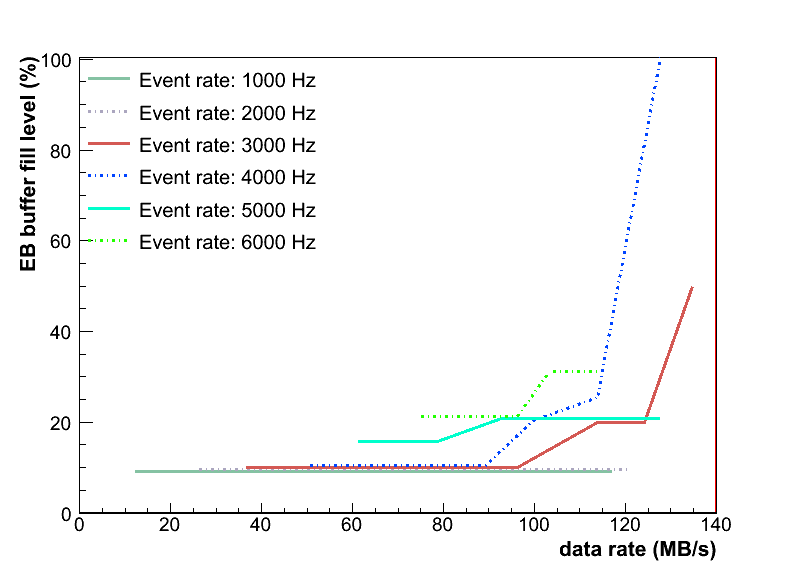 daq_netmem: fill level of buffers vs data rate:
daq_netmem: fill level of buffers vs data rate:
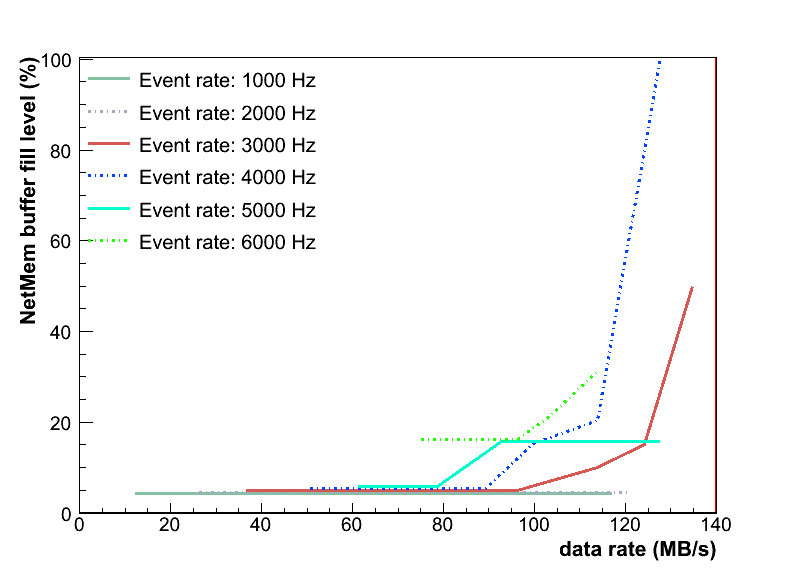
Event Builder performance:
Conclusions: Event Builder shows stable operation. The fill level of buffers is far below critical. The fill level for the test-3 is given in MB in a table below for different event rates.
An open problem: if I generate a huge subevent (size = 100 kBytes) once per about 1000 events for every data source asynchronously, then daq_evtbuild gets blocked and
daq_netmem's buffers get fully filled. Under investigation.
Some results:
Observations:
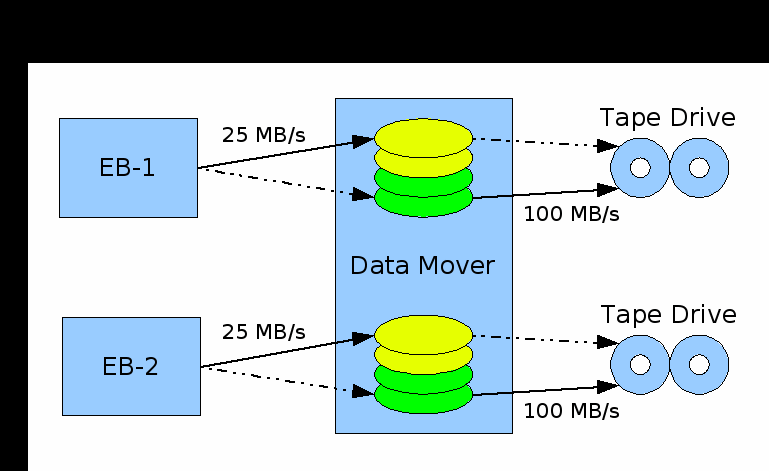
Several attempts to run with 25 MB/s data rate ended up with hanging Data Mover (when writing to a tape is enabled). (We had also one hang with 15 MB/s data rate). However there seems to be no problem when only one EB writes to tape via RFIO.
Under investigation.
New tests (10.07.2009) showed good performance of writing to tape. Setup: 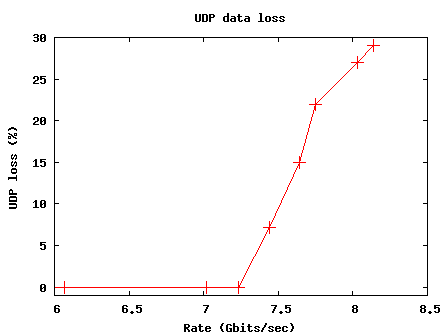
Overall old 10Gbit NICs (lxhadeb02/03) seem to be better than new 10Gbit NICs (lxhadeb01/04). In most of the tests (up to 6Gbit/sec) the UDP loss for lxhadeb02/03 is 0%.
Tests with 90 subsystems:
Test-1 with 90 subsystems (no writing to hard disk, no rfio)
The test system: TOF-0, TOF-1, TOF-2, TOF-4 VME CPUs --> netgear 8 port switch --> foundry switch --> Event Builder Conditions:- I used TOF-0, TOF-1, TOF-2 and TOF-4 VME CPUs. 23/22 daq_rdosoft processes per CPU.
- Water mark was set to 32 kB.
- subevent sizes were Gaussian-like smeared
- No writing to hard disk, no rfio to Data Mover.
- net.core.netdev_max_backlog = 10000
- net.core.rmem_max = 4194304 (nettrans.c:openUdp(): requests 1 MB queue)
- EB buffer = 8 MB (x2x2). Cannot go to 16 MB because 16x2x2x90 = 5.6 GB (more than available memory).
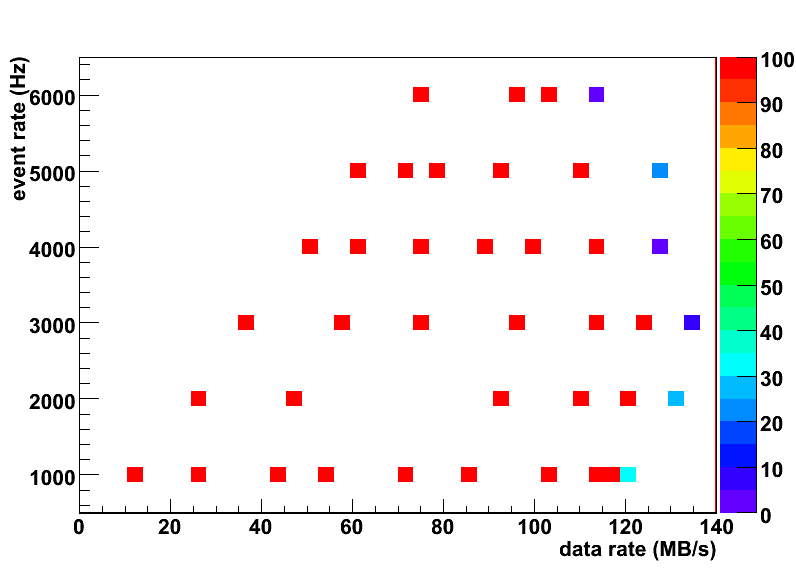
- The Event Builder efficiency (z-axis) is plotted as a function of the event rate and the data rate. The efficiency is defined as 100% minus an amount of discarded events (in %). Efficiency drops rapidly down above 100 MB/s data rate. In fact, this is most likely related to a huge load on VME cpus which run 23/22(x2) soft readout processes each and to a limited bandwidth of the netgear switch. Event Builder seems to be able to go further above this limit.
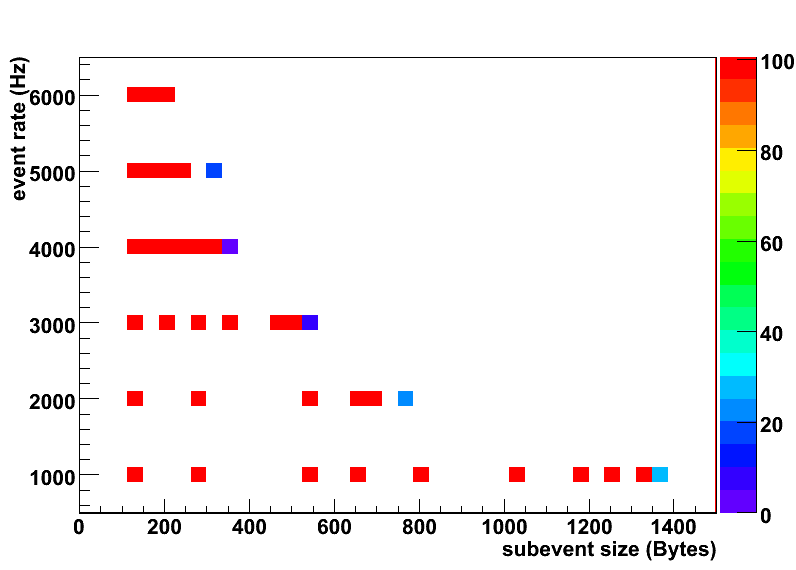
- The Event Builder efficiency (z-axis) is plotted as a function of the subevent size and the data rate. This is different representation of the same plot.
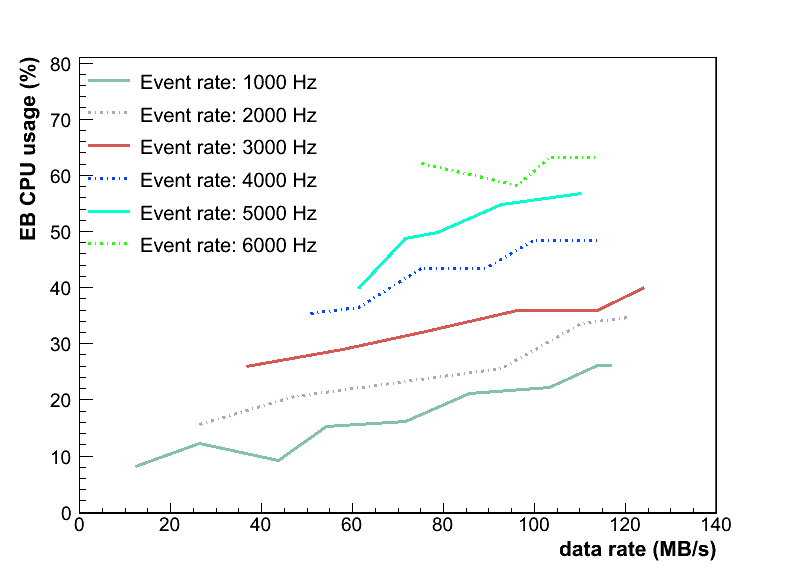
- CPU usage of Event Builder as a function of the data rate. At the data rate of about 100 MB/s the Event Builder tend to accumulate all CPU time. There is an interesting trend: daq_evtbuild CPU usage depends on both the event rate and the data rate. While daq_netmem CPU usage depends mostly on the data rate.
daq_netmem CPU usage vs data rate:
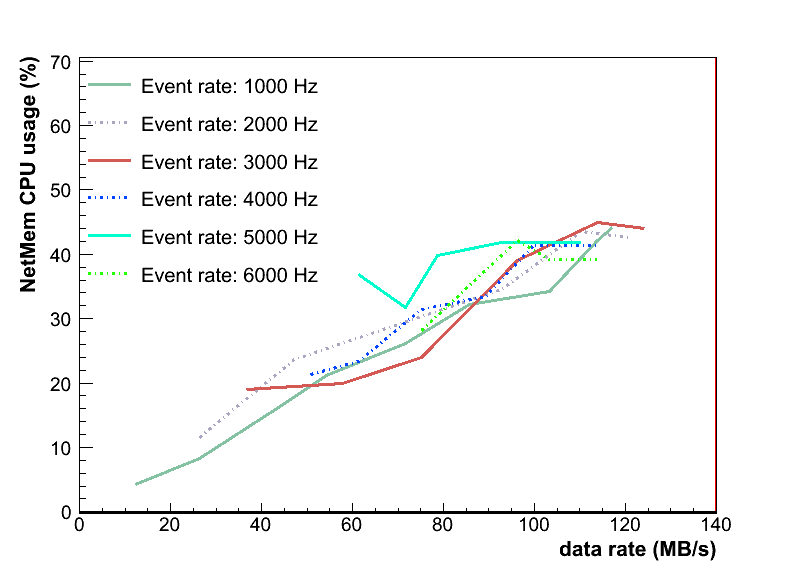
- Fill levels of the buffers of Event Builder as a function of the data rate. The fill levels of buffers stay as low as 10%/20% up to a data rate of 100 MB/s. Above 100 MB/s the test system is going out of control which leads to a synch problem between the data sources. Consequently the buffers get filled.
daq_netmem: fill level of buffers vs data rate:
Test-2 with 90 subsystems (no writing to hard disk, no rfio)
Difference from previous test-1: different sources have different sizes of subevents. Subevent sizes were Gaussian-like smeared. In this test I was only increasing an event rate. The subevent sizes were constant (given in table below). The Event Builder buffers were accordingly tuned. Configuration of data sources:| Number of sources | subevt size | Buffer size |
| 60 | 116 Bytes | 2x4 MB |
| 20 | 338 Bytes | 2x8 MB |
| 10 | 1.17 kBytes | 2x32 MB |
| ev rate | data rate | disc evt | cpu evtbuild | cpu netmem | load | buff evtbuild | buff netmem |
| Hz | MB/sec | % | % | % | % | % | |
| 1000 | 23 | 0 | 12 | 10 | 0.5 | 10 | 5 |
| 2000 | 46 | 0 | 20 | 19 | 0.6 | 10 | 10 |
| 3000 | 69 | 0 | 30 | 28 | 0.7 | 20 | 10/20 |
| 4000 | 95 | 0 | 44 | 32 | 0.9 | 20/30 | 20 |
Test-3 with 90 subsystems (no writing to hard disk, no rfio)
Difference from test-2: Now I additionaly generate a huge subevent (size = 100 kBytes) once per about 10000 events for every data source asynchronously. Event Builder performance:| ev rate | data rate | disc evt | cpu evtbuild | cpu netmem | load | buff evtbuild | buff netmem |
| Hz | MB/sec | % | % | % | % | % | |
| 1000 | 23 | 0 | 12 | 10 | 0.5 | 20 | 10 |
| 2000 | 46 | 0 | 20 | 18 | 0.5 | 20 | 15 |
| 3000 | 69 | 0 | 33 | 29 | 0.6 | 20 | 15 |
| 4000 | 95 | 0 | 42 | 35 | 0.9 | 20/30 | 20 |
| Event rate | source numbers | buff size | evtbuild buff fill level | netmem buff fill level |
| Hz | MB | MB | MB | |
| 1000 | 0-59 | 8 | 1.6 | 0.8 |
| 60-79 | 16 | 3.2 | 1.6 | |
| 80-89 | 64 | 12.8 | 6.4 | |
| 2000 | 0-59 | 8 | 1.6 | 1.2 |
| 60-79 | 16 | 3.2 | 2.4 | |
| 80-89 | 64 | 12.8 | 9.6 | |
| 3000 | 0-59 | 8 | 1.6 | 1.2 |
| 60-79 | 16 | 3.2 | 2.4 | |
| 80-89 | 64 | 12.8 | 9.6 | |
| 4000 | 0-59 | 8 | 1.6 | 1.6 |
| 60-79 | 16 | 4.8 | 3.2 | |
| 80-89 | 64 | 19.2 | 12.8 |
Test-4 with 90 subsystems
Difference from test-3: now I additionally write the data to a local hard disk and to a Data Mover via RFIO. Event Builder performance:| ev rate | data rate | disc evt | cpu evtbuild | cpu netmem | load | buff evtbuild | buff netmem |
| Hz | MB/sec | % | % | % | % | % | |
| 1000 | 23 | 0 | 20 | 15 | 0.8 | 20 | 10 |
Tests with 60+60 subsystems, two Event Builders and one Data Mover
The final aim of these tests is to understand the performance of the EB system when writing to the different mass storage systems. Of a special interest is the performance of the Data Mover (DM) when two Event Builders are writing to it. We will run Event Builders with the following settings:- writing the data to /dev/null. (This is an ideal case)
- lxhadesdaq: writes to Lustre.
- lxhadesdaq: writes to Lustre + to local disks.
- lxhadesdaq: writes to Lustre + to DM via RFIO, hadeb06: writes to the same DM via RFIO
- EB-1 : lxhadesdaq (receives 25 MB/s in total from 60 sources)
- EB-2 : hadeb06 (receives 25 MB/s in total from 60 sources)
- Data Mover : a new type of a server with two hardware raid arrays (8 and 7 disks). Its performance is supposed to be much better than a performance of the old Data Movers (which had only one raid array).
| EB | Local disk | Lustre | DM | ev rate | data rate | disc evt | cpu evtbuild | cpu netmem | load | buff evtbuild | buff netmem |
| kHz | MB/sec | % | % | % | % | % | |||||
| hadeb06 | - | - | - | 3 | 35 | 0 | - | - | 0.3 | 10 | 10 |
| lxhadesdaq | - | - | - | 3 | 35 | 0 | - | - | 0.4 | 10 | 10 |
| lxhadesdaq | - | yes | - | 2 | 25 | 0 | - | - | 0.4 | 10 | 10 |
| lxhadesdaq | yes | yes | - | 2 | 25 | 0 | 25 | 10 | 0.9 | 10 | 10 |
- EB alone is very stable. Runs with 60 sources (data rate of 25 MB/s) during one week without problems.
- Writing to the Lustre seems to be also OK. During about 24 hours EB wrote about 2 TB of data to the Lustre without any problem.
| EB | Local disk | Lustre | DM | ev rate | data rate | disc evt | cpu evtbuild | cpu netmem | load | buff evtbuild | buff netmem |
| kHz | MB/sec | % | % | % | % | % | |||||
| hadeb06 | - | - | yes | 1 | 15 | 0 | 8 | 4 | 0.2 | 10 | 10 |
| lxhadesdaq | - | yes | yes | 1 | 15 | 0 | 13 | 6 | 0.3 | 10 | 10 |
| hadeb06 | - | - | yes | 2 | 25 | 0 | 14 | 11 | 0.5 | 20 | 15 |
| lxhadesdaq | - | yes | yes | 2 | 25 | 0 | 24 | 10 | 0.5 | 20 | 15 |
| setup | result |
| one EB -> DM -> Tape Drive | OK |
| two EBs -> DM | OK: 2.6 TB written to pool during 20 hours |
| two EBs -> DM -> two Tape Drives | DM hangs after 20 min |
| two EBs -> DM -> one Tape Drive | DM hangs after 20 min |
- 30+30 data streams to two EBs (30+30 MB/s) on lxhadeb01
- Each EB writes 30 MB/s data to tape via RFIO.
- Also parallel writing to Lustre from Data Mover was successful.
- Should still be tested with 90 data sources.
Tests of the Event Builder on 64-bit platform
The aim of the test: the performance of the EB executables recompiled on a 64-bit platform. Setup:- Event Builder: hadeb06
- Data sources run on TOF CPUs
- Works fine with a number of data sources upto 95 (data rate of 45 MB/s)
- Opens buffers with a total size upto 12 GB (out of 12 GB available)
- RFIO connection to the Data Mover works
- If there are 96 data sources, EB does not switch a buffer for a data stream from 96th source. This leads to filled buffers and discarded packets. Whereas on 32-bit platform EB works fine with 100 sources. (under investigation)
Tests of UDP packet loss
Tests with four 1Gbps NICs (bonding)
- General test with iperf: server on lxhadeb01 and clients on VME CPUs
- In HADES VLAN with bonding could go only up to 1 Gbps with four clients without UDP loss (expected 4 Gbps).
- Test with Event Builders on lxhadeb01 and soft readouts on VME CPUs
- UDP buffer overflow
- Measurement: netstat -su ("packet receive errors" in UDP section)
- Result: "packet receive errors" counter does not increase. However Netstat displays the statistics from the transport layer only. The netstat statistics do not account for datagram drops happening at layers.
- Overflow of Event Builder buffers (never observed)
- Buffers of EBs are monitored, fill levels < 10%.
- Bonding leads to UDP loss???
- UDP buffer overflow
Tests with 10Gbps NIC
- lxhadeb02 and lxhadeb03 are interconnected via 10Gbps switch
- Both servers have 10Gbps PCI Express cards
- Test setup:
- lxhadeb02 client: iperf -c 140.181.91.154 -u -l 60k -w 512k -b 5g -p 65005 -i 1
- lxhadeb03 server: iperf -s -u -p 65005 -l 60k -w 512k
# -w 512k = UDP buffer size (iperf opens a double of 512k = 1 MByte)
# -l 60k = UDP datagram size
# -b 5g = send with a speed of 5 Gbits/sec
# -i 1 = report each second
# -u = UDP protocol
- Results:
#Expected Rate TX Rate (Client) RX Rate (Server) UDP loss
#(Gbits/sec) (Gbits/sec) (Gbits/sec) (%)
4.03 4.03 4.03 0
5.02 5.02 5.02 0
6.07 6.07 6.07 0
7.02 7.02 7.02 0
7.23 7.23 7.23 0
7.44 7.44 6.91 7.2
7.64 7.64 6.49 15
7.80 7.75 6.06 22
8.40 8.03 5.83 27
9.00 8.14 5.78 29
- More tests of all four servers (lxhadeb01/02/03/04) with iperf. Setup: three servers send UDP packets to a fourth server (three servers run three UDP clients and the fourth server run three UDP servers).
| Data rate (Gbit/sec) | UDP loss (%) | UDP loss (%) | UDP loss (%) | UDP loss (%) |
|---|---|---|---|---|
| lxhabeb01 | lxhadeb02 | lxhadeb03 | lxhadeb04 | |
| 1 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 |
| 3 | 0-0.05 | 0 | 0 | 0-0.05 |
| 4 | 0.05 | 0-0.05 | 0-0.05 | 0.05 |
| 5 | 0.2-1.0 | 0-0.2 | 0-0.2 | 0-1.0 |
| 6 | 0.5-5.0 | 0-0.2 | 0-0.2 | 0.5-5.0 |
| 7 | 26 | 20 | 50 | 23 |
| 8 | 40 | 40 | 50 | 50 |
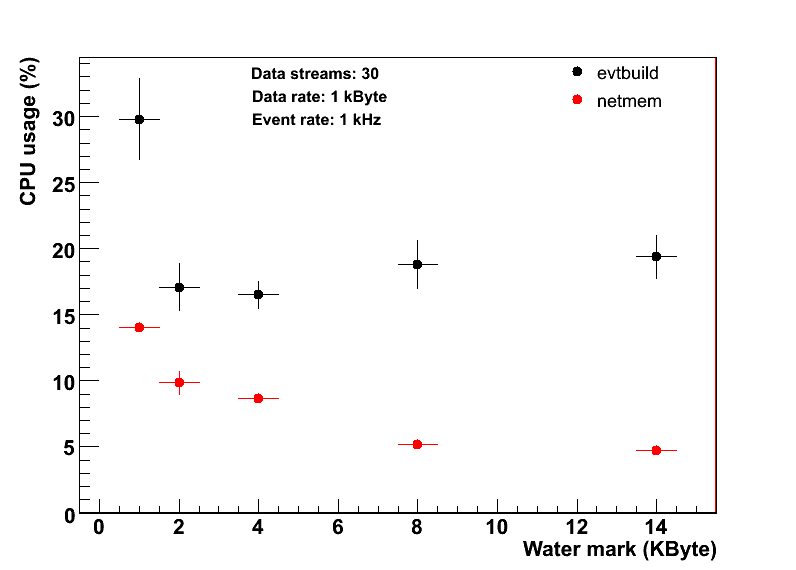
CPU usage vs water mark
- CPU usage vs wmark is shown on the pic below. CPU usage by netmem goes up as a water mark decreases. Netmem should handle larger amount of UDP packets. There is also a sudden jump of CPU usage by evtbuild at a water mark of 1 kB. Do not have yet an explanation.
Test of complete system with 4 EB Servers, 16 data streams and RFIO to tape
- The EB setup: 16 EB processes receiving 16 data streams from the DAQ (11 MB/s per stream) and writing via RFIO to 5 Data Movers
- Results: Very stable operation, Data Movers did not show any hanging behavior, all streams were properly distributed over Data Movers even after 20 restarts following one after another without any delay, no data loss after several ours of intensive testing.


| I | Attachment | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|
| |
cpuvswmark.gif | manage | 7 K | 2009-08-18 - 16:48 | SergeyYurevich | cpu usage vs wmark |
| |
ebbuffvsdatarate.gif | manage | 297 K | 2008-02-08 - 20:25 | SergeyYurevich | daq_evtbuild: fill level of buffers vs data rat |
| |
ebcpuvsdatarate.gif | manage | 297 K | 2008-02-08 - 20:12 | SergeyYurevich | daq_evtbuild CPU usage vs data rate |
| |
evtvsdatarate.gif | manage | 344 K | 2008-02-08 - 19:48 | SergeyYurevich | EB effic vs event rate and data rate |
| |
evtvssubevtsize.gif | manage | 344 K | 2008-02-08 - 20:03 | SergeyYurevich | EB effic vs subevt size and data rate |
| |
nmbuffvsdatarate.gif | manage | 297 K | 2008-02-08 - 20:29 | SergeyYurevich | daq_netmem: fill level of buffers vs data rate |
| |
nmcpuvsdatarate.gif | manage | 297 K | 2008-02-08 - 20:26 | SergeyYurevich | daq_netmem: fill level of buffers vs data rate |
| |
setup_1.1.gif | manage | 11 K | 2008-05-29 - 15:09 | SergeyYurevich | test setup |
| |
udp_loss.png | manage | 2 K | 2010-02-05 - 12:30 | SergeyYurevich | UDP loss vs Data rate |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Edit | Attach | Print version | History: r16 < r15 < r14 < r13 | Backlinks | View wiki text | Edit wiki text | More topic actions
Topic revision: r16 - 2010-11-29, SergeyYurevich
Copyright © by the contributing authors. All material on this collaboration platform is the property of the contributing authors.
Ideas, requests, problems regarding Foswiki Send feedback | Imprint | Privacy Policy (in German)
Ideas, requests, problems regarding Foswiki Send feedback | Imprint | Privacy Policy (in German)